 Cuando cumplió 9 años le regalaron su primera computadora: una TK83. Ese mismo día empezó a programar jueguitos y desde entonces ha sido autodidacta en el mundo de la informática.
Cuando cumplió 9 años le regalaron su primera computadora: una TK83. Ese mismo día empezó a programar jueguitos y desde entonces ha sido autodidacta en el mundo de la informática.
Autor Lic. Martín Marcelo Sgattoni
Unless we have a deck of tarot cards, predicting is difficult . When you anticipate an action by assuming that something is going to happen before it happens is predicting. Foretelling whether it will rain tomorrow by flipping a coin is a prediction. A lousy prediction, but at the end of the day, we are talking about one. So the problem with predictions is to achieve the highest degree of certainty. It’s difficult to bet it right most of the time. Predictive models are representations of reality with a utilitarian purpose. In general, they seek to solve problems, improve processes, advance solutions. But if the model does not adjust to reality, it will predict badly.
The central problem is that there are no models built on future data; we only have documented the past. The predictive modeling of the future is an act of faith because we build it on past data with techniques that project it into the uncertain future.
In marketing, there are several models that can be built to predict and improve our strategies. The most common one is the modeling of our target’s future behaviors. We know how our customers behaved because we know what they’ve consumed, but what we would really like to know is how they’re going to behave. This model is known as Predictive Demand Analysis.
Why would it be interesting knowing how a customer will behave?
First of all, if I know what a customer is going to consume in the future, I can define more precisely the promotional investment I am willing to make. I’m not going to invest the same effort for a customer that I estimate will buy one chocolate as for another one that I suspect will buy 20.
This data is known as Client Lifetime Future Value (CLFV). Be careful! Many companies calculate an old CLFV from the past: they add up what the customer bought and that is your CLFV. Okay, it’s an indicator, but it’s not predictive, it’s historical.
Other companies calculate the Future CLFV by simply projecting it. This is wrong. You have to be careful if you use this KPI to predict. Assuming that future behavior will simply be a linear continuity of the past can lead to serious mistakes.
Predictive demand modeling allows me to detect customers at risk of Churn. The Churn Rate is a probabilistic KPI. It consists of assigning each customer a % risk of abandonment. It’s something like assigning a loyalty index, how confident I am that they will still be my client.
Let’s look at ways to predict the Churn Rate.
Types of predictive modeling 1: the stone age.
Churn Rate is the probability that someone will leave me in a determinate period in the future. There are several ways to calculate it. Let’s assume an elementary version to understand the concept: I can take the date of each customer’s last purchase and assume that the more time has passed, the higher the Churn Rate of that customer. The probability that the customer has abandoned me for the competition increases as the days go by without buying from me again. It is very basic, but it is a valid Churn KPI if I do not have another more accurate tool.
But wait, maybe I have customers who buy rarely because they buy large volumes or simply because they don’t buy often. But when they do buy, they do it with us.
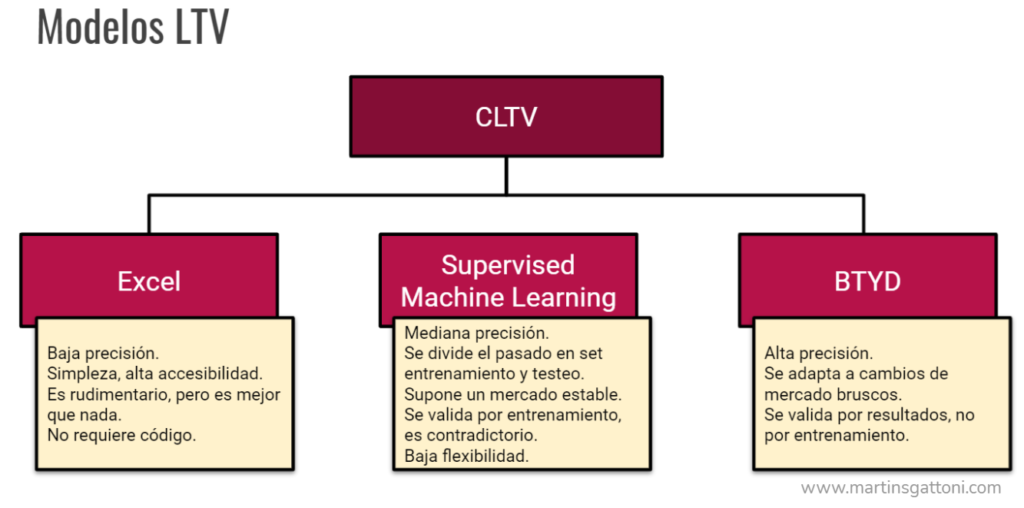
I could also build manually what is known as a composite KPI: I analyze several variables, assign them a weight and based on all of them I assign a Churn Rate value. For example, I could consider: recency, historical purchase volume, the number of times they complained, their satisfaction surveys, etc. If I don’t have a more sophisticated predictive tool, this method is a good starting point. A bit outdated too, but it’s still a model.
The problem is that the variables are assigned weights manually, and that always gives the model a certain amount of arbitrariness. It is a construction that in Data Science is known as “a priori”. It contains a certain amount of subjectivity.
Types of predictive modelling 2: the rear-view mirror.
If we are looking for something more sophisticated, we can already count on Machine Learning tools to build the models. The most common is the construction of supervised models. These are algorithms that automatically learn from past cases that have already been solved.
The approach would be something like this: for a long time I collect information from my customers: demographic, geographic, behavioural, etc. variables. I also record which of those customers abandoned me (churned).
With that data I train a supervised machine learning model and show it the data of my current customers so that it assigns a prediction to each one based on what it learned from the old data. The model will tell it which of the current customers are most similar to the customers it churned out. This is a prediction.
I didn’t want to say this approach is wrong… but it is. Let me explain my opinion. First of all, it should be noted that supervised modelling is the most commonly offered by the companies that provide these services. This is because it is what is taught in most of the machine learning courses that are proliferating today, following the trend of artificial intelligence. Be careful, just because something is plentiful does not mean it is good.
My opinion is that supervised machine learning does not apply to this specific marketing problem for several reasons.
Firstly, it requires a lot of historical data, which means not having a good predictive tool during the collection period. During that time, customers are lost, they churn because we do not detect them and we are not acting preventively on them.
Secondly, the supervised approach assumes that what happened before will happen in the future. And in marketing this does not apply. The market moves, mutates, migrates, evolves .
Types of predictive modelling 3: Florensys!
Florensys, our Predictive Demand Analysis tool, uses a third, more sophisticated approach that performs far better than the two I have already explained.
Florensys’ modelling does not need to be trained on past cases already churned out. It works on current customer data.
The first thing it does is to analyse the distribution of general target behaviours: consumption frequencies, volumes, sequences, inactivity ranges, trends, evolutions, etc.
In essence, what Florensys does, after analysing the distribution of behaviours, is to assign each individual two probabilities for each future promotional cycle: What is the probability that this customer will buy from me again in X cycle ? and What is the probability that this customer will stop buying from me forever in X cycle ?
In essence, it’s like flipping 2 coins for each customer whose behaviour I want to predict. But they are not common coins. Both are unbalanced, the probability of each side falling is not 50%. This disproportion is specific to each coin for each customer and arises from the analysis of the distributions previously calculated on the complete target.
The Florensys model is self-calibrating to give more weight to recent behaviour. In this way it achieves greater accuracy in prediction.
This approach makes the tool useful right away: by running on recent data, it doesn’t need old, churned out cases to train itself. This means that from day one it is already making predictions and giving us the tools to detect the target at risk and act preventively on it.
Another advantage of the probabilistic approach is that if the target changes its behaviour substantially (ex. a pandemic occurs, or a disruptive product appears), the model is reformulated and maintains accuracy automatically. In the case of a supervised model, if something like this happens, the trained model must be discarded and start from scratch.
Lic. Martín Marcelo Sgattoni



Comentarios recientes