 Cuando cumplió 9 años le regalaron su primera computadora: una TK83. Ese mismo día empezó a programar jueguitos y desde entonces ha sido autodidacta en el mundo de la informática.
Cuando cumplió 9 años le regalaron su primera computadora: una TK83. Ese mismo día empezó a programar jueguitos y desde entonces ha sido autodidacta en el mundo de la informática.
Autor Lic. Martín Marcelo Sgattoni
Predecir es difícil, salvo que tengamos un mazo de cartas de tarot. Adelantar una acción suponiendo que algo va a suceder antes de que ocurra, es predecir. Predecir si mañana va a llover tirando una moneda es una predicción. Una pésima predicción, pero una predicción al fin.
Entonces el problema con las predicciones es lograr que tengan el mayor grado de certeza. Que acierten la mayoría de las veces.
Los modelos predictivos son representaciones de la realidad con un fin utilitario. Por lo general buscan resolver problemas, mejorar procesos, adelantar soluciones. Pero si el modelo no se ajusta a la realidad, va a predecir mal.
El problema central es que no existen modelos armados sobre datos futuros, solo tenemos documentado el pasado. El modelado predictivo del futuro que hacemos es, en cierta medida, un acto de fe, porque lo construimos sobre datos del pasado con técnicas que los proyectan hacia el futuro incierto.
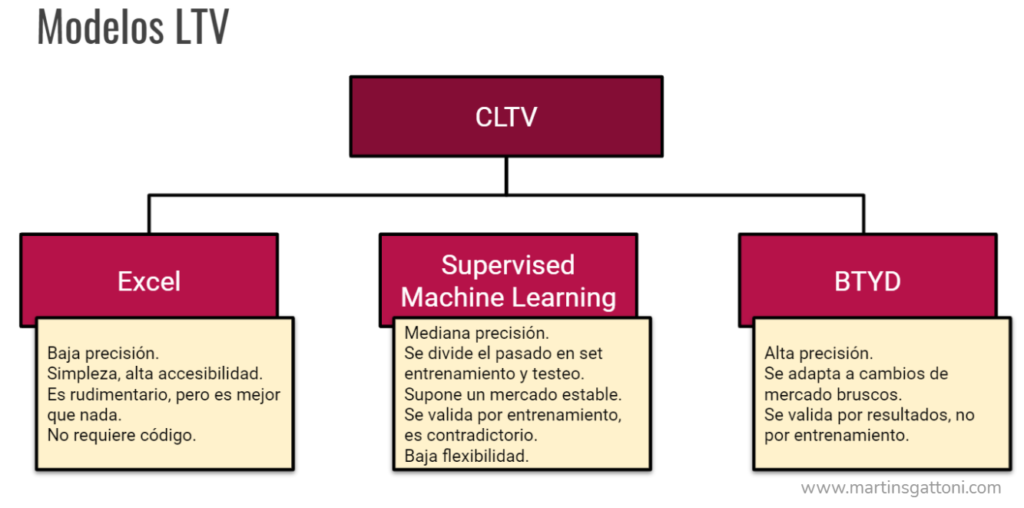
En el rubro del marketing existen varios modelos que se pueden construir para predecir y mejorar nuestras estrategias. El más común es el modelado de las conductas futuras de nuestro target. Sabemos cómo se comportaron nuestros clientes porque conocemos lo que consumieron, pero en realidad lo que nos gustaría saber es cómo se van a comportar. A este modelo se lo conoce como Análisis Predictivo de la Demanda.
¿Para qué nos sirve saber cómo se va a comportar un cliente?
Bueno, en primer lugar, si yo se lo que un cliente va a consumir a futuro puedo definir con más precisión la inversión promocional que estoy dispuesto a hacer. No voy a invertir el mismo esfuerzo para un cliente que estimo me va a comprar un chocolate que para otro que sospechó me comprará 20.
Este dato se lo conoce como Client Lifetime Value Futuro (CLTV). Ojo, muchas empresas calculan el CLTV pero del pasado: suman lo que el cliente compró y eso es su CLTV. Está bien, es un indicador, pero no es predictivo, es histórico.
Otras empresas calculan el CLTV Futuro simplemente proyectándolo. Eso está mal. Hay que tener cuidado si se usa este KPI para predecir. Suponer que la conducta futura será simplemente una continuidad lineal del pasado puede llevar a cometer graves errores.
En segundo lugar, el modelado predictivo de la demanda me permite detectar clientes en peligro de Churn. El Churn Rate es un KPI probabilístico. Consiste en asignarle a cada cliente un % de riesgo de abandono. Es algo así como asignarle un índice de fidelidad, qué tan tranquilo estoy de que me seguirá consumiendo.
Veamos entonces formas de predecir el Churn Rate.
Tipos de modelado predictivo 1: la edad de piedra.
Churn Rate es la probabilidad de que alguien me abandone en un periodo determinado del futuro. Hay varias formas de calcularlo. Supongamos una versión elemental para entender el concepto: yo puedo tomar la fecha de la última compra de cada cliente y suponer que cuanto más tiempo haya pasado, mayor Churn Rate tiene ese cliente. La probabilidad de que me haya abandonado por la competencia crece a medida que transcurren los días sin que me compre nuevamente.Es muy básico, pero es un KPI de Churn válido si no cuento con otra herramienta más precisa.
Pero cuidado, tal vez tengo clientes que compran pocas veces porque compran volúmenes grandes o simplemente porque no lo hacen seguido. Pero cuando compran lo hacen con nosotros.
También podría construir manualmente lo que se conoce como un KPI compuesto: analizo varias variables, les asigno un peso y en base a todas ellas le asigno un valor de Churn Rate. Por ejemplo, podría considerar: la recencia, el volumen de compra histórico, la cantidad de veces que se quejó, sus encuestas de satisfacción, etc. Si no cuento con una herramienta predictiva más sofisticada, este método es un buen punto de inicio. Un poco anticuado también, pero no deja de ser un modelo.
El problema es que se asigna peso a las variables de manera manual y eso siempre le da al modelo una cuota de arbitrariedad. Es una construcción que en Data Science se conoce como “a priori”. Contiene una cuota de subjetividad.
Tipos de modelado predictivo 2: el espejo retrovisor.
Si buscamos algo más sofisticado podemos contar ya con herramientas de Machine Learning para construir los modelos. Lo más común es el armado de modelos supervisados. Son algoritmos que aprenden automáticamente sobre casos pasados ya resueltos.
El enfoque sería algo así: durante mucho tiempo recolecto información de mis clientes: variables demográficas, geográficas, conductuales, etc. También registro quiénes de esos clientes me abandonaron (churnearon).
Con esos datos entreno un modelo de machine learning supervisado y le muestro los datos de mis clientes actuales para que les asigne una predicción a cada uno en base a lo que aprendió con los datos viejos. El modelo dirá quiénes de los clientes actuales se parecen más a los exclientes que churnearon. Esto es una predicción.
No voy a decir que este enfoque está mal… pero está mal. Paso a explicar mi opinión. Antes cabe avisar que el modelado supervisado es el que más ofrecen las empresas que dan estos servicios. Esto sucede porque es lo que se enseña en la mayoría de los cursillos de machine learning que proliferan en la actualidad subidos a la ola de la moda de la inteligencia artificial. Hay que tener cuidado, que algo abunde no quiere decir que sea bueno.
Mi opinión es que el machine learning supervisado no aplica para esta problemática específica del marketing por varios motivos.
En primer lugar, requiere mucha data histórica, esto implica no contar con una buena herramienta predictiva durante el periodo de recolección. Durante ese tiempo se pierden clientes, churnean porque no los detectamos y no estamos actuando preventivamente sobre ellos.
En segundo lugar, el enfoque supervisado supone que lo que pasó antes sucederá igual en el futuro. Y en marketing esto no aplica. Los mercados se mueven, mutan, migran, evolucionan.
Tipos de modelado predictivo 3: ¡Florensys!
Florensys, nuestra herramienta de Análisis Predictivo de la Demanda, utiliza un tercer enfoque más sofisticado que rinde muy por encima de los dos que ya expliqué.
El modelado de Florensys no necesita entrenarse con casos pasados ya churneados. Trabaja sobre los datos de clientes actuales.
Lo primero que hace es analizar la distribución de las conductas generales del target: frecuencias de consumo, volúmenes, secuencias, rangos de inactividad, tendencias, evoluciones, etc
En esencia, lo que hace Florensys, luego de analizar la distribución de las conductas, es asignarle a cada individuo dos probabilidades para cada ciclo promocional futuro: ¿Cuál es la probabilidad que este cliente me compre nuevamente en el ciclo X? y ¿Cuál es la probabilidad que este cliente me deje de comprar para siempre en el ciclo X?
En esencia es algo así como tirar 2 monedas para cada cliente cuyas conductas quiero predecir. Pero no son monedas comunes. Ambas están desbalanceadas, la probabilidad de caer de cada cara no es del 50%. Esa desproporción es propia para cada moneda de cada cliente y surge del análisis de las distribuciones que calculó previamente sobre el target completo.
El modelo de Florensys se va autocalibrando para dar más peso a las conductas recientes. De esta manera obtiene mayor precisión a la hora de predecir.
Este enfoque hace que la herramienta sea útil enseguida: al ejecutarse sobre datos recientes, no necesita casos viejos ya churneados para entrenarse. Esto quiere decir que desde el día uno ya está haciendo predicciones y dándonos herramientas para poder detectar al target en peligro y actuar preventivamente sobre el mismo.
Otra ventaja del enfoque probabilístico es que si el target modifica sustancialmente su conducta (por ejemplo ocurre una pandemia, o aparece un producto disruptivo), el modelo se reformula y mantiene la precisión automáticamente. En el caso de un modelo supervisado, si ocurre algo así, el modelo ya entrenado debe descartarse y empezar de cero.
Lic. Martín Marcelo Sgattoni
Serie: Marco Teórico de Florensys.



Comentarios recientes